最強の日本語オーディオペア
こんにちは、うえしゅうです。
先週BLDの大会があり、その帰りの食事会でまっくんが悪牛君スタイルの2レイヤー式オーディオペアを使っていると聞いて、自分でもそれを取り入れられないかと色々考えていました。何日か考えて悪牛君のナンバリングを改造し、この一週間実験的に使ってみたんですが、めちゃくちゃ覚えやすすぎて自分でも感動しています。
今回の記事では自分の考案した新しい日本語オーディオペアを公開し、その中身の説明をしていこうと思います。
2レイヤー式オーディオペアとは
2レイヤー式オーディオペアとは、1つのステッカーに2つの音素(A, B)を割り当て、1文字目だったらA、2文字目だったらBを使うといったように文字の順番によって音素を使い分ける方式です。ナンバリングが2レイヤーあるということですね。
今のところ、悪牛君、まっくん、なっきー君、たいへい君、onninn君あたりが使っているらしいです。
ちなみにこの方法はダブルナンバリングとも呼ばれていましたが、ダブルナンバリングは何文字目かによらずもっと柔軟なタイミングで使い分ける方式なので、それと異なる呼び方としてまっくんが2レイヤー式と呼び始めました。
自分のオーディオペア表
今回自分が使っているオーディオペア表を公開します。
uesyuu’s audio pair list with 2 layer
ナンバリング
自分のナンバリングは以下のような感じです。母音の位置以外は基本的にどこに何が配置されていても大丈夫です。
1レイヤー目
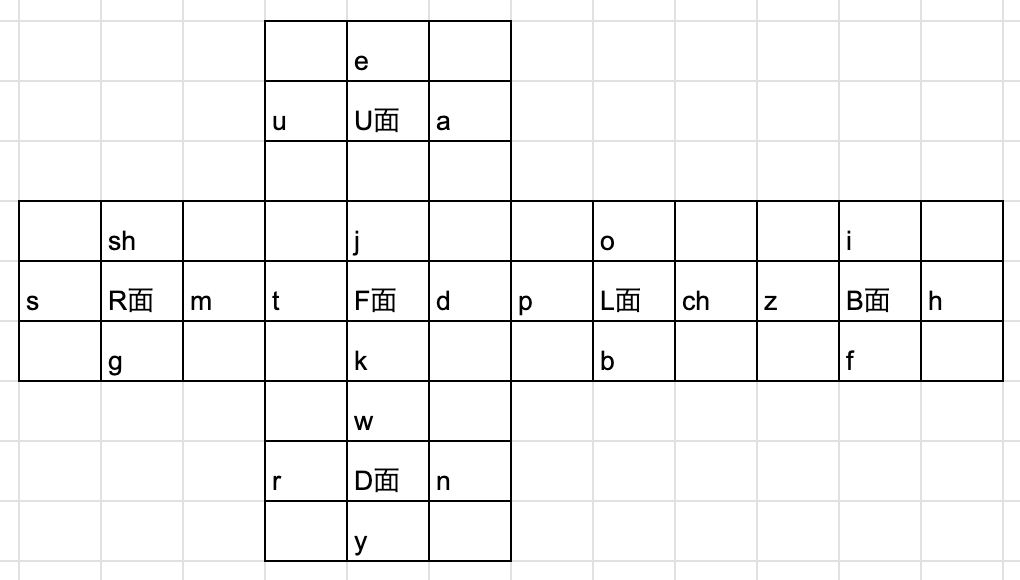
2レイヤー目
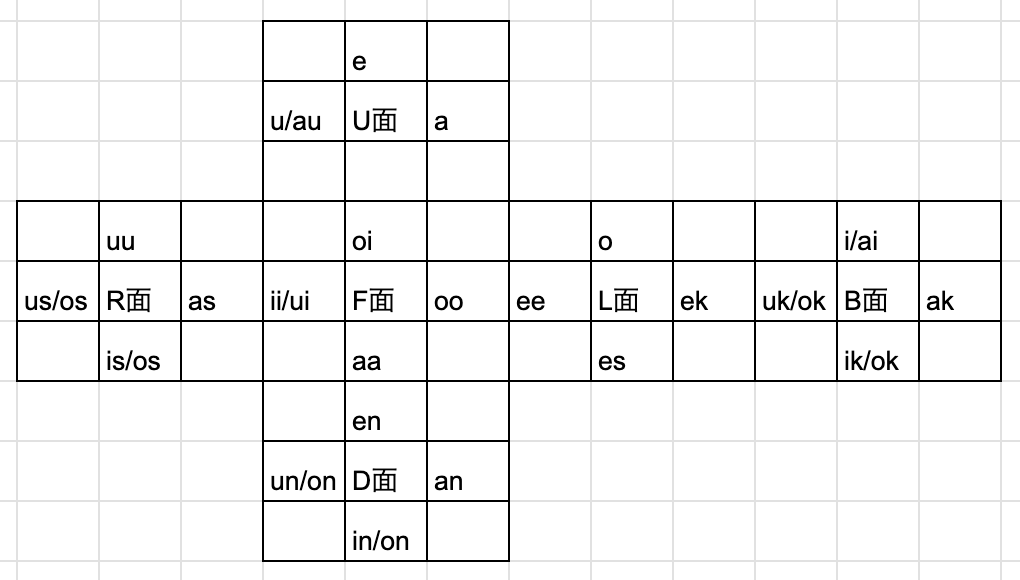
使う音素
使う音素は以下の通りです。
1文字目のレイヤー
a i u e o (あいうえお)
k s t n h m y r w (かさたなはまやらわ)
g z d b p (がざだばぱ)
sh ch f j (しちふじ)
2文字目のレイヤー
a i u e o (あいうえお)
aa ii uu ee oo (あーいーうーえーおー)
ak ik uk ek (あくいくうくえく)
as is us es (あすいすうすえす)
an in un en (あんいんうんえん)
oi (おい)
例外処理
1文字目が母音の場合
1文字目が母音だった場合は、2文字目はそのステッカーの1文字目のレイヤーの音素を使います。
例えばUR-FDは普通にやると[a, aa]になってしまうので、1文字目のレイヤーを使って[a, k]にします。
また、この方法にすると発音が被ってしまったり言いづらかったりする組み合わせが数件あるのですが、以下にその場合の変換を書いておきます。
ah ih uh eh oh -> a i u e o (hは発音せず1文字にする)
ar ir ur er or -> aru iru uru eru oru
ay iy uy ey oy -> kyai ii kyui kei kyoi (頭にkyをつける)
aw iw uw ew ow -> kyau kiu kyuu keu kyou (頭にkyをつける)
被る音について
以下の音はどうしても同じ音になってしまいます。
zi ji
si shi
hu fu
yi i
wu u
そのため、このうち前者はoを使い被りをなくします。
例えば、[j, in]はjinでそのまま、[z, in]は被ってしまうのでiをoに変えてzonにします。
また、2文字目が母音単体もしくは長母音だった場合は二重母音を使って被りをなくします。
例えば、[j, i]はjiでそのまま、[z, i]は被ってしまうのでiをaiに変えてzaiにします。
ナンバリング表の2文字目レイヤーのところにも、iとuの箇所はそれが使えなかった時用の代替音素が書かれています。
発音しづらい音について
[tu]と[du]は日本語ではあまり使わないためちょっと発音しにくいです。
そのため、tとdについても2文字目にu系が来たらoに変えるようにしています。
例外の例外
2文字目がuuの場合の代替音素だけナンバリング画像に書いてないのですが、この場合は特別に以下の変換を行います。
huu -> hyuu (fuuと被らないようにする)
wuu -> uu
採用したナンバリング案の利点
長音・撥音・促音が使える
日本語は英語などと違って母音や子音の数が少ないのですが、その代わり長音・撥音・促音というものがあります。
- 長音: 伸ばし棒をつけて発音する音 (例: あー)
- 撥音: 文字の間に入る「ん」の音 (例: あんこ)
- 促音: 文字の間に入る「っ」の音 (例: きって)
特に英語話者はこのあたりを区別するのがとても難しいらしいです。例えば「おばさん」と「おばあさん」は日本人的には違う単語とわかりますが、英語話者にとっては同じに聞こえてしまうみたいです。不思議ですね。
というわけで、せっかく我々は日本人なのだからその特性を生かさないわけにはいかないですよね?
長音は2文字目のaaのような長母音、撥音は2文字目のanのような音素で表現しています。
促音ですが、これは特定の2ペアが繋がった時に発生します。例えば、[m, as] [s, an]という2ペアが連続した場合、1ペア目の2文字目はsで終わり2ペア目の1文字目はsから始まっているので、sとsが重なり「っ」となって「まっさん」という促音の入った音に変化するのです。日本人であれば口が勝手にそう動くと思います。
促音が発生するのは以下の表のタイミングです。
| 1ペア目の2文字目 | 2ペア目の1文字目 |
|---|---|
| ak, ik, uk, ek, ok | k, ky |
| as, is, us, es, os | s, sh |
連続した2ペアがくっつく場合がある
先程の促音と似ているのですが、1ペア目の2文字目が子音でかつ2ペア目の1文字目が母音の場合はそれをくっつけて発音することができます。
例えば、[m, as] [a, n]は1ペア目の2文字目がsで2ペア目の1文字目がaなのでくっついて「まさん」と発音されます。
実質的に音が1文字減る感じですね。
まっくんもこの方法を使ってるみたいです。
1パーツ2ステッカー両方に母音を振ったため、母音の出現率が上がる
今回の話と直接関係があるわけじゃないですが、UBとBU、URとRUにそれぞれ母音を振っているため、この2パーツを通った際に必ず母音が発生します。また、この2パーツは新しくループを作る時に優先して選ぶパーツなので、始点と終点でそれぞれ母音が発生し、より1文字が出る確率が高まると思われます。
もっと正確に言うと1文字が全然出ない確率が低くなる、ですね。前のナンバリングで1文字が0個とか1個なのに6ペア12文字だった時にすごく覚えづらかったので、なるべく1文字が出ないバッドケースを減らす意味でこの方法を採用しました。
この辺の話は自分の過去の記事で触れています。
使ってみた感想
このナンバリングで一週間ほど使ってみたんですが、まず思ったのが「12文字余裕で覚えられる!」です。
今回使った長音・撥音・促音はそれぞれ2モーラに値するのですが、音節としては1音節です。
例:
- お, と, う, さ, ん -> 5モーラ
- お, とう, さん -> 3音節
感覚として、音はモーラ単位ではなく音節単位で覚えられる感覚があるので、音をめちゃくちゃ減らせてる感覚があります。平均して3音は減っていると思うので、12文字が9音になり人間の記憶のマジックナンバーにギリギリ入り覚えやすくなっているのではないかと思います。
もう一つは「発音しにくい音がない」というものです。
日本語は原則として母音で終わる言語です。そのためオーディオペアで2文字目に子音が来ると途端に発音しづらくなります。
しかし、語尾が「ん」もしくは無声子音の時だけは日本語でも末尾子音で発音が可能になることがあります。
無声子音とは「k, s, sh, t, ch, ts, h, p」のことで、例えば「そうです」の末尾はuが抜けて「そうでs」と発音する日本人が多いと思います。
今回のオーディオペアでは2文字目に「ak, as, an」を採用していますが、nは一旦置いておいてkとsは無声子音です。そのため子音ではありますが2文字目に置いても違和感無く発音できるのだと思います。
最後にこのナンバリングで生成された文字列を1つ紹介します。
kik ra puk is shan te (キクラプキッシャンテ)
pukとisが繋がりプキスとなり、さらにisとshanが繋がって促音となりプキッシャンになります。そして長音・撥音・促音は1音節のため音節単位で考えると、この文字列は7音節となります。12文字が7音節!流石に凄すぎます。
終わりに
実験的に今使ってみているオーディオペアのナンバリングを紹介してきました。
12文字が余裕で覚えられるのに毎日驚きすぎて、今週と来週の大会練習が全然手につかない現状です。
当分はこのナンバリングで慣らしてみて、次のBLD大会までに実践で使えるレベルにまで持っていけたらなと思っています。
このナンバリング案が日本人BLDerの参考になれば幸いです。
それでは。